
In this project, I wanted to scrape the job search results from Apple, Amazon, Facebook, Google, and Netflix to help expedite my job search. It is a tedious thing to go to each site to get all the jobs results for different cities, so I figured I would automate it. Here is the thing, I have never scraped data off a site before but really wanted to try using the tools available to do it. Now I do realize that these sites probably don’t want you scraping their data, so do this at your own risk. This is the long but fun journey to finally figure out how to do this.
Also, to give credit to where credit is due, I learned a lot of this from the data science program over at dataquest.io. Check them out because it’s a really great program.
This project was supposed to be an easy exercise in web scraping using Beautiful Soup and dumping the data into a simple Excel file. This turned out not being that kind of project.
Since there are five sites used, I will only go over the two most difficult, those being Facebook and Amazon. The Python code for Apple, Google, and Netflix can be found on my GitHub page here.
This post will only go over Facebook, to avoid turning into something as long as a CVS coupon printout and boring you. I am working on the post for Amazon’s code and will have that up soon.
To start, each one of these sites had their own issues which prevented me from creating one big script to run on all five sites. So I created one for each but can run them all at once. For Facebook, I could run Beautiful Soup and it ran well, but as you will see, it grouped multiple cities in one cell for the same job. I wanted each job to be unique with its own city. So that took a while to figure out. For Amazon, there are just so many jobs to scrape and I kept getting blocked after a while, but I figured that out too. Of course, I am just beginning, so there must be better ways to do this and I am all for feedback to make this better.
Okay, that is enough talk. Let’s look at some code.
Scraping Facebook’s Job Search Page
To begin, here’s the full code I used for Facebook:
(Click anywhere in the code to bring up a full page view.)

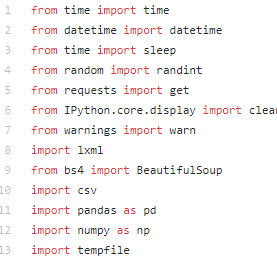
Modules to Import
These are the modules I had to import to make it work:
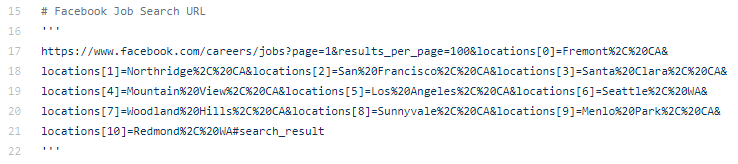
The Job Search URL
When searching for jobs on Facebook, you can search by city. Here is the URL used for the cities I needed. There must be a way to make this look better using parameters or something for each city instead of hard coding it this way but I just needed it to see how many pages to scrape. Plus, I found it easier to iterate through one URL instead of creating parameters for each city separately.
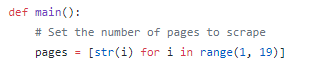
The Main Function
I created a main function that creates a certain number of pages(responses) within a certain known page range. You have to look at the jobs results from the URL above to determine how many pages you will need to scrape. At the time of this writing, they have 19 job search page results for 100 results per page. So that’s almost 1,900 jobs search results.
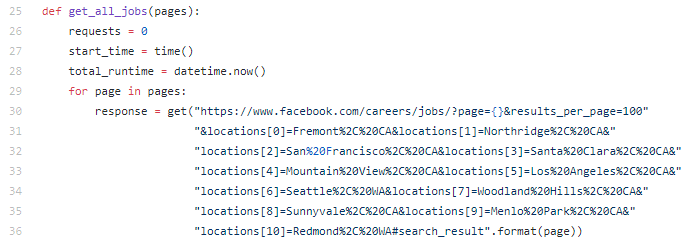
Monitoring the loop while it’s working
From this main function, a pages variable is created and used in the def get_all_jobs(pages) function at the beginning of the code. This function will monitor the frequency of each request and show a time stamp of how fast each request is sent to the site.
The requests variable will count the number of requests through each iteration of pages.
The start_time variable will set the start time using the time function from the time module that was imported.
The datetime.now() module will be added to the total_runtime variable and used to show how long it took to run the entire script.
For each page requested, the URL of the results page is called and assigned to the response variable.
Here, through each successful iteration, the count is increased and added to the requests variable.

This next section will pause the loop between 8 – 15 seconds and display the number of requests, how fast each request is sent, and the total time it took to run the entire script.
- The
sleepfunction will pause randomly between 8 – 15 seconds - The
timefunction is added to thecurrent_timevariable - The current time is subtracted from the starting time of the loop and added to the
elapsed_timevariable - The variables are printed out to display the results
- The
clear_outputfunction will clear the output after each iteration and replace it with information about the most recent request. This will show each result one at a time instead of a long list of results.
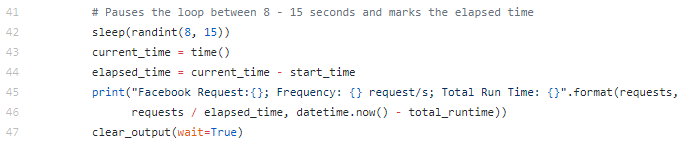
The request frequency displayed when the script is executed.

Here, we check if the request’s response was successful. A 200 code is what we want to but if a non-200 code is found, a warning will be thrown.

For the last ‘if’ statement below, if the requests are more than requested, the loop will break. If we stay within the number of requested pages, we should be fine. In this case, there are 19 requests we are making because there are 19 pages.
The yield from get_job_infos(response) at the bottom allows that value to be made available to the def get_all_jobs(pages) function.

Scraping with Beautiful Soup
In the get_job_infos(response) function, Beautiful Soup is used to parse html tags from the response variable.
- The Beautiful Soup function takes in the
responsevariable as text and useslxmlto parse the html. - It then finds all
atags that also contain the_69joclass and puts that value into thejob_containersvariable. - A
forloop iterates throughjob_containersand finds more values from other tags and classes then puts those values into the variables for site, title, location, and job link.
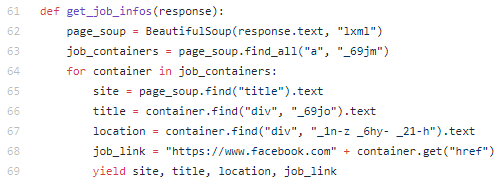
Writing to a temp file
These last couple sections were what really stumped me but after an awful amount of hours searching Stack Overflow and Google, I finally figured it out. Well, I figured out one way of doing it.
This creates a temporary CSV file with a header row and writes the output from the get_all_jobs(pages) function to this temporary file.

Separating Cities Into Their Own Cell
The biggest problem I ran across was trying to figure out how to parse multiple cities listed on each row for the same job. I needed each row to be for a single job for each city. This meant I needed duplicate rows for the amount of cities listed in the location column and show one city for that row.

Since I had a little experience with Pandas library, I found it easier to put the data into a data frame and parse out the cities by doing the following:
- Read the CSV file into the
fb_dfvariable. - Take that variable and isolate the location column. Then use regular expressions to split the cities at each spot where it finds a comma before a space and capital letter next to a small letter, like so: New York, NY, Seattle, WA, Menlo Park, CA
- The expand parameter is set to True in order to put each city in it’s own cell
- The pandas add_previx function labels the columns with ‘city_’ for columns that have cities and appends the column number that city is in.
- The fillna function fills any empty cell it pulled from the Location column after the split with a NaN value, in case there are any.


- Set the data frame index using the first four columns. These four columns are Website, Title, Location, and Job URL.
- Then use the
stackfunction to duplicate the rows based on the number of cities split. - Reset the index
- Copy the split cities, paste into the location column, and strip of any white space.

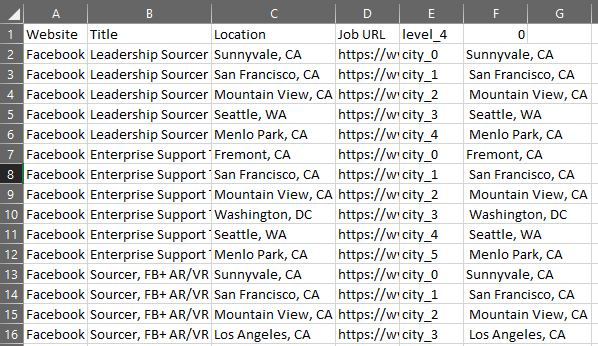
Finally, drop the last two columns and write to a new CSV file without an index.

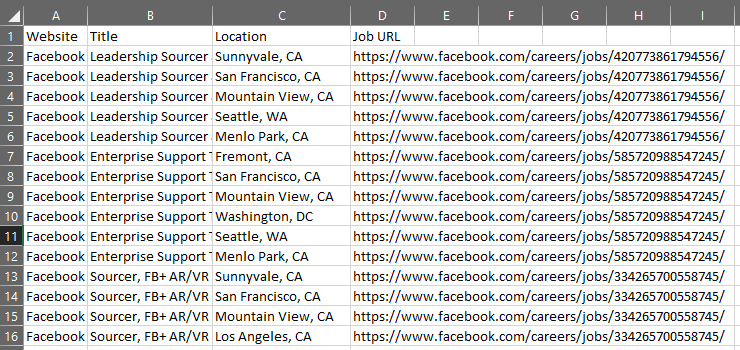
This file can be executed on its own since it calls the main function but I’ll be importing this into another file and running it from there along with the other scraping files to make one big CSV file with search results from each site.
I’m always open to feedback, so let me know how to make this better. Also, I’d like to find a way to analyze this data somehow. I could probably map all the jobs geographically but there must be other things to analyze as well.
Heck, maybe there’s an API to get this info to begin with but it was a great challenge anyway.